Summary:
- Failure is not always a problem and in Amy Edmonson’s recent book, Right Kind of Wrong: The Science of Failing Well, she categorizes them into three types: Basic, Complex, and Intelligent.
- The type of failure you experience depends on the problem domain you are working in and can be Safe-to-Fail or Fail-Safe.
- People at different levels of an organization will look at the same problem in different domains based on their levels of expertise. This can cause issues when addressing failure.
- Blaming individuals for failure is dangerous and can incentivize them to hide failure, creating a culture prone to more failure.
One of the common refrains I hear is making sure people are held accountable. This is usually said as a way to prevent failure in the future. It presumes two things that are frequently incorrect:
- Failure is a problem.
- Lack of accountability is a problem.
Failure is only sometimes a problem
A failure, at its core, is an undesirable outcome. We tried to accomplish X, and instead, we got Y. Amy Edmondson, author and Professor of Leadership at Harvard Business School, categorizes failure into three main categories:
- Basic Failures – Prevent these
- Where Access to the right way exists but isn’t used or followed
- Complex Failures – Anticipate & Mitigate
- A set of factors combine in novel ways to produce failures in reasonably familiar contexts.
- Intelligent Failures – Promote & Celebrate
- Undesired Results of thoughtful forays into novel territory.
For previous readers of Chalk-X, if you think these fit into an earlier article, you are correct. These types of failure map well into the Cynefin model I’ve discussed here. This means that the problem space you are working in dictates the kind of failure you are likely to have.
Here is a quick review of the Cynefin model that categorizes dealing with problems into 4 main domains:
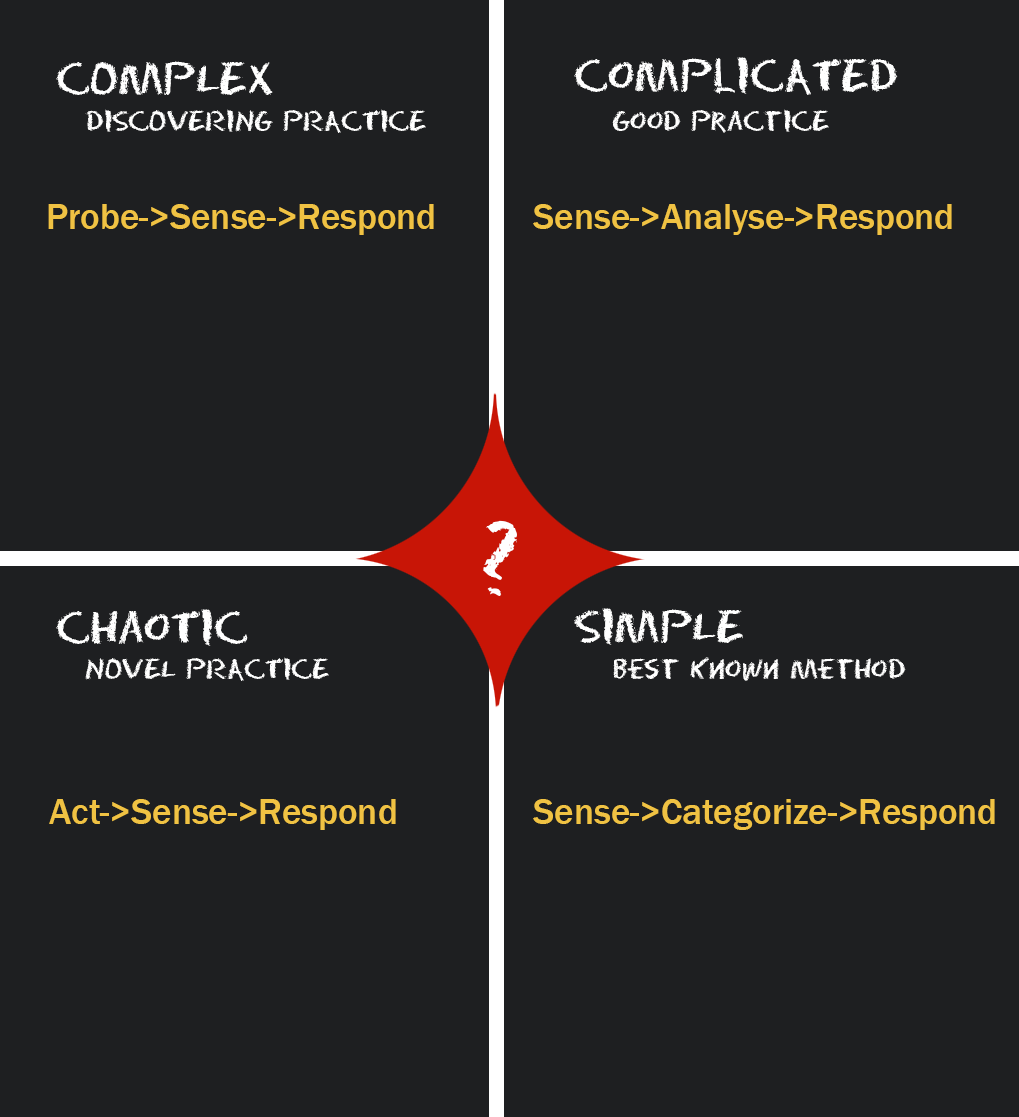
As mentioned in the previous article, you can split the Cynefin domains into two higher-level domains: Safe-to-Fail and Fail-Safe.

Reinforcing the importance of understanding what kind of work you are doing helps you figure out how to mitigate or embrace failure. Let’s look at some examples in each category.
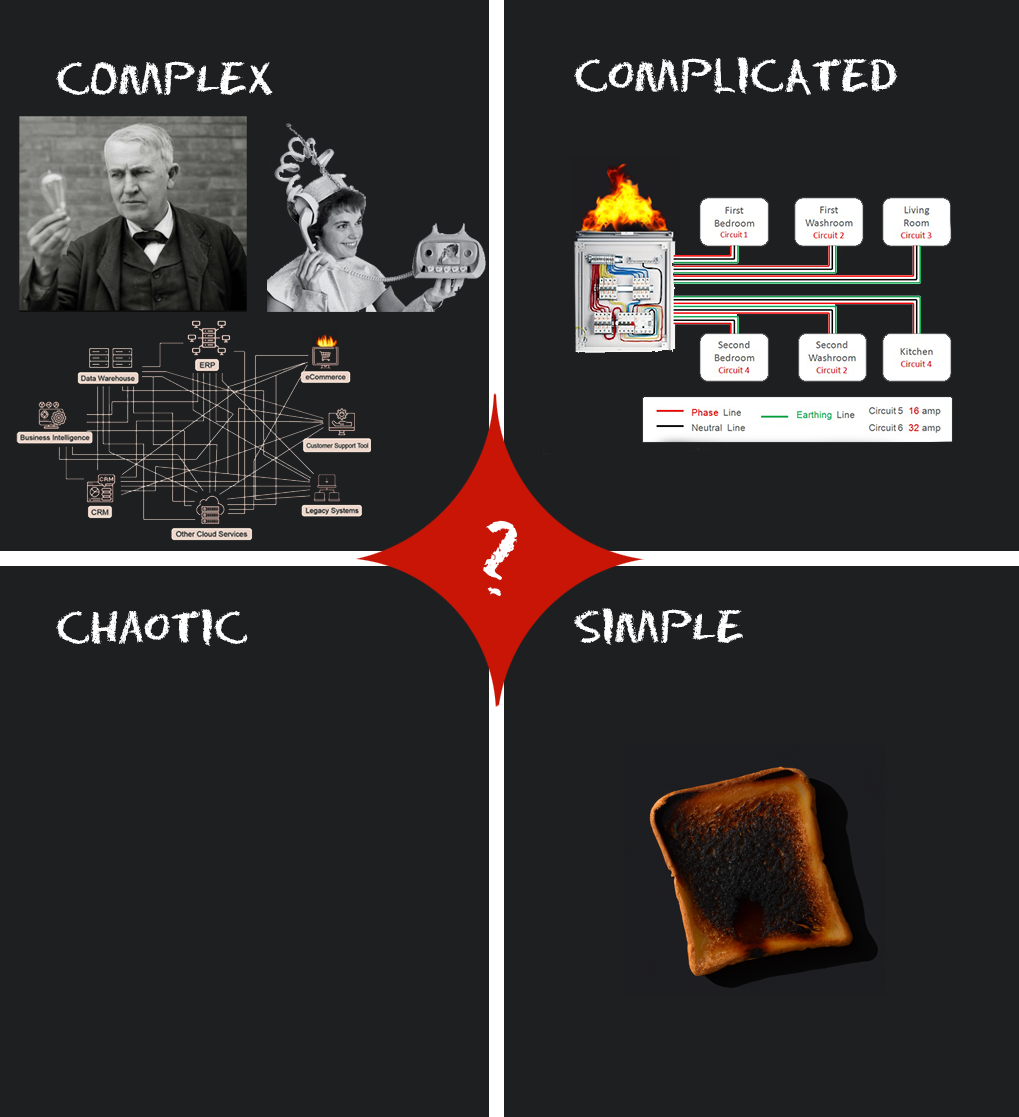
Basic
You are prone to fundamental failures if you are in the simple or complicated domain. Training, checklists, and procedures can mitigate failure in these domains. If you leave the bread in the toaster too long, it burns. You can start a fire if you don’t follow electrical standards or the provided circuit diagram.
This is what most people think of when they “blame” someone for failure. It is worth noting that blaming people for failure is a dangerous activity because it incentivizes them to hide failure, making it worse. This is one of the critical points of Amy Edmondson’s recent book, Right Kind of Wrong: The Science of Failing Well.
When we fail in the basic domain, the goal is to blame the person only if they truly were negligent or malicious. In this domain, we need to look for improved procedures, standards, and recipes to prevent that failure from happening again. Note that you may be working on a problem in a complex domain when trying to rewrite procedures and standards.
Complex Failures
This is usually where the “how” may be known, but the outcome is uncertain. It requires collaborative experts and testing to get to a known destination. Rocket booster testing is a great example of this:

All the math and modeling in the world doesn’t predict an outcome until you test it. I am speaking of modern rocket testing as initially, they weren’t sure what would work and what wouldn’t. Those sorts of tests were Intelligent failures. They had no idea what had worked in the past, but more on that in a minute.
When implementing off-the-shelf software, complex failures happen constantly in a company’s IT departments. The individual system implementations are known, but introducing it into a system of systems is, as I have analogized, like bringing a wild animal into a farm. In some more complex systems, the farm is more like a jungle. While you may bring in expert animal handlers, they have never been in your farm/jungle. The environment is unknown even though the system is understood.
Here, we can mitigate the failure, but sometimes they happen anyway because combination of factors is novel or unknown. Excellence, not perfection, is the goal. Here, we need a premortem, experts, assumption analysis, and lots of testing to try and mitigate failure.
Intelligent Failures
These are where new project work typically comes up. This is developing a new, unique product, software, business processes, scientific discovery, etc. These failures include Edison creating the light bulb, figuring out how a liquid rocket works, or a video phone. The first attempts and these solutions don’t work out because no one has done it successfully.
Her 2011 article Strategies for Learning from Failure in Harvard Business Review outlined five criteria for categorizing something as Intelligent failure.
A summary of her criteria for Intelligent Failures are:
- Explore an opportunity because there is yet to be a recipe.
- It is novel territory, and we don’t know how to do it.
- We spent time beforehand making key assumptions explicitly articulated; a method I recommend is assumption mapping.
- Keeping the cost and scope as small as possible. After all, novel ideas are rarely successful the first time.
- Generating learning that informs the next steps. What is the point of doing it if we only try and do nothing with the learning?
Failures here need to be accepted, and the learning from failure awarded. Building psychological safety from these kinds of failures creates a culture of innovation.
How often is your company asking, “What did we learn?” instead of “Who caused the problem?” One leads to growth and the other stagnation.
Different problems at different levels
One of the things Edmonson highlights is the asymmetry of knowledge at different levels in an organization. This asymmetry leads to treating problems, solutions, and failures in a way that damages the organization financially and psychologically. Let’s look at some different scenarios to highlight this realization.
Simple but complex
Leaders think an issue is basic, but in reality, it is complex. Let’s look at a common example:
A CEO of a large retailer goes to a conference and learns about a very cool AI-powered new financial system company, FNC. He signs up to buy the new financial software FNC. He wants all those promises of the vendor implemented in his company before year-end so that he can put out a better earnings report and better forecast. In his mind, he bought the software; it is a SaaS vendor, no installation is needed, and the system just needs their data. This problem should be simple.
However, people within the organization have never seen anything like this FNC software. They can’t seem to integrate their sales data into the software. Worse, no system collects the data required for the FNC system to work as advertised. They’ll need to change point-of-sale systems and implement new integrations to get that new data, which will take a long time, and every transaction before that conversion won’t have the data required by FNC. This means the year-end earnings report will always be incomplete, and likely, forecasts will be off. This is a complex failure waiting to happen.
This is the equivalent of saying I got a BBQ that is supposed to be easy to assemble, except we need instructions, tools, and expertise to build it. Without a recipe, the problem is not simple. And our failure to build the BBQ is likely.

This is where accountability comes in. If the CEO holds the IT team accountable for not delivering, it could be because he believes it was a simple problem they failed to adhere to standards and procedures. The accountability in this situation isn’t the problem. If accountability means punishment (see Homer above), then it is unlikely information will make it to the CEO about the issues around the FNC software.
It doesn’t even have to be an overt punishment. It could simply be sticking to the previous timeline, overworking the organization, and never taking any responsibility as the leader to highlight his own mistakes. This sends the signal that “failure isn’t tolerated and I won’t listen”.
This creates an environment without psychological safety, which Edmonson highlights in her book is necessary for a successful organization. This abuse of accountability leads to another failure scenario.
Complex but complicated
One of the things Edmonson highlights is how often the unknown-unknowns are only unknown at the decision-maker level. How frequently do people lower in the organization know this is a wrong decision but don’t have the authority to make a difference when they see a failure coming? If they’ve been held “accountable” when they didn’t own the problem or the decision, why highlight issues with an upcoming decision? It won’t make a difference, and you may get in trouble.
Suppose our CEO plans on launching a new product but is still determining its success and ability to manufacture or sell. Why would anyone in the organization highlight apparent issues they see?
Create a culture of disaster
In 1985, the NASA Space Shuttle Challenger blew apart 73 seconds into its flight. Killing all seven crew members on board. This was a complex failure, but people within the organization knew it might happen. Many engineers within NASA, like Bob Ebeling, tried to highlight the risk before launch, but as one NASA leader commented, the organization was in such a go mode no one couldn’t stop it.
Richard Feynman, the famous physicist and teacher, was on the review board that examined the causes of the disaster. Feynman interviewed people throughout NASA. While some engineers put the chances of catastrophe around one in 100, some managers thought them to be closer to one in 100,000. Regarding failure, it is essential to remember that humans have no sense which detects a change in risk. To prove this, note the size and success of casinos and gambling websites. The differences in estimating risk came down to levels of expertise vs political pressure. Feynman once said in an interview:
For a successful technology, reality must take precedence over public relations, for Nature cannot be fooled.
Richard Feynman
How often is your organization being fooled? How often do you reset timelines based on what the lowest level people in the organization learn/say? How often is it ignoring risk, or intuiting chance rather than calculating it? Is that self-deception costing lives?

Leave a comment